学习和使用 JMeter 过程中遇到的问题和解决办法。
jmeter.properties 配置
# 界面中文
language=zh_CN
# 解决响应体乱码
sampleresult.default.encoding=UTF-8
Windows 压测配置
问题:并发过大时,JMeter 报错:java.net.SocketException: Socket operation on nonsocket: connect
解决:缩短 TIME_WAIT 状态 TCP 连接回收时间和添加 TCP 动态端口范围,保证在大并发场景下操作系统的端口资源可用
# 在 HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters 下新建 DWORD(32位) 值,重启生效
TcpTimedWaitDelay 30(10进制)
MaxUserPort 65534(10进制)
模拟浏览器请求
一般默认 http 请求只会访问后端接口,若测试时需要模拟和浏览器一样的操作,有加载耗时,可以在 http 请求高级里勾选从 HTML 文件获取所有内含的资源,这样请求时会下载 jss,css,图片资源。
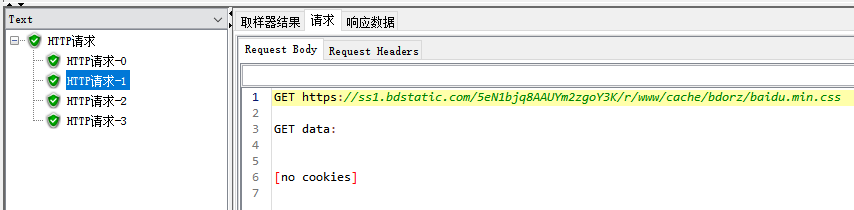
JSON 提取器
$表示根元素,然后一级级属性往下去找,先找到data,再往下子节点找到content[*]表示该节点下有多个子节点,接着找到id
Names of created variables:参数名称
JSON Path expressions:提取表达式
Match No.(0 for Random):匹配规则,-1 所有,0 随机,1 第一个
Compute concatenation var:如果有匹配到多个值,选择此项,会将全部值保存到 _ALL,并使用逗号分割每个值,注意Match No. (0 for Random) 需要为 -1 才有效,不然只能匹配到一个值了
Default Values:没提取到就给默认值
正则表达式提取器
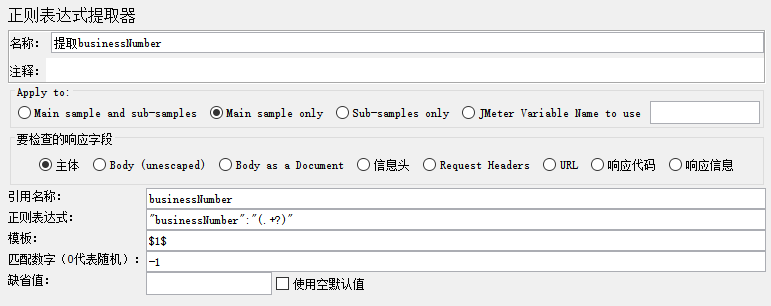
要检查的响应字段:样本数据源,默认选主体。
引用名称:其他地方引用时的变量名称 (re_token),可自定义设置,引用方法:$
正则表达式:数据提取器,()括号里为你要获取的的值,如:”token”: “(.*?)”
模板:$$ 对应正则表达式提取器类型。-1 全部,0 随机,1 第一个 2 第二个,以此类推,若只有一个正则一般就填写 $1$
匹配数字:正则表达式匹配数据的所有结果可以看做一个数组,匹配数字即可看做是数组的第几个元素。 -1 表示全部,0 随机,1 第一个,2 第二个,以此类推。若只要获取到匹配的第一个值,则填写 1
缺省值:匹配失败时的默认值,可以随便写个,不写也可以,或者勾选失败时候使用空值
例如:假设提取到了响应结果中所有的id,引用名称为ids,可通过计数器+循环控制器来遍历请求每个id,循环次数为:${ids_matchNr},计数器开始值为1,递增1,引用名称num,变量则为:${__V(ids_${num})}
XPath 提取器
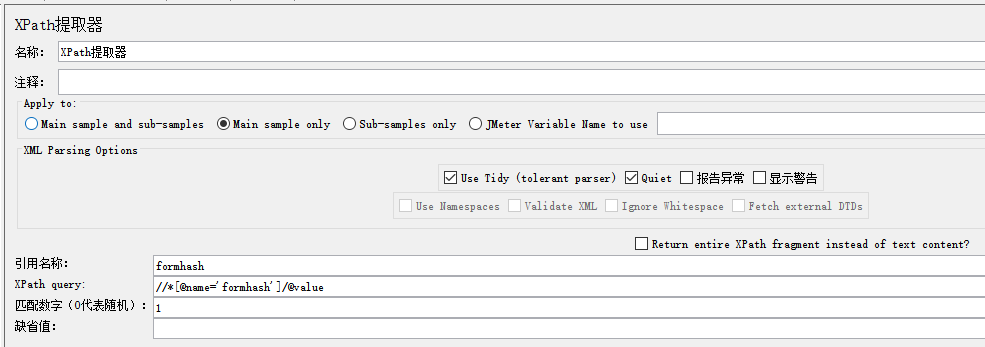
Use Tidy:当需要处理的页面是 HTML 格式时,必须选中该选项,当需要处理的页面是 XML 或 XHTML 格式(例如,RSS 返回)时,取消选中该选项。
引用名称:参数的变量名称
XPath query:用于提取值的 XPath 表达式://*[@name='formhash']/@value
匹配数字:-1 所有,0 随机,1 第一个
缺省值:取不到的时候默认值
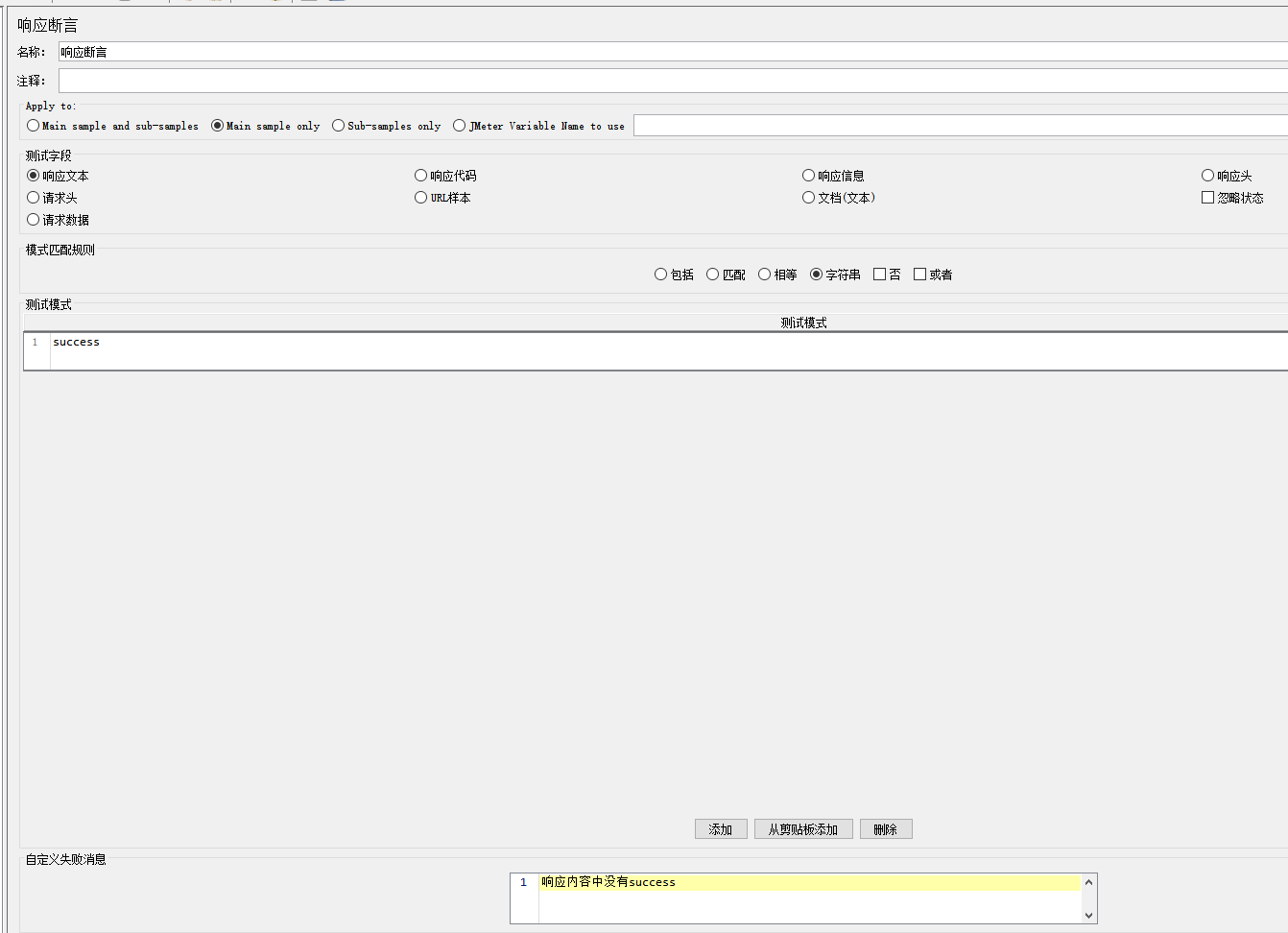
响应断言
检查返回的结果,断言内容与响应结果不符时,在聚合报告里则为异常请求
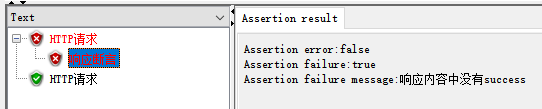
如果(If)控制器
${__jexl3(${Number}>1)}
${__groovy(${Number}>1)}
计数器
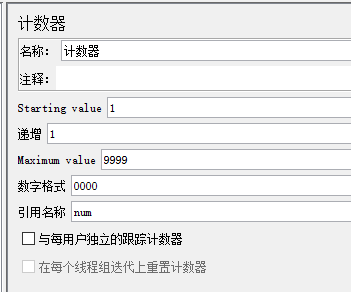
Starting value:计数器的初始值,第一次迭代时,会把该值赋给计数器
递增:每次迭代后,给计数器增加的值
Maximum value:计数器的最大值,如果超过最大值,重新设置为初始值,默认的最大值为 Long.MAX_VALUE,2^63-1
数字格式:可选格式,比如 0000,格式化为 0001 (从初始值开始,不足的位数补 0);默认格式为Long.toString(),但是默认格式下,还是可以当作数字使用
引用名称(Reference Name):用于控制在其它脚本中引用该值,形式:$(num}
与每用户独立的跟踪计数器(Track Counter Independently for each User):全局的计数器,如果不勾选,即全局的,比如用户 #1 获取值为 1,用户 #2 获取值还是为 1;如果勾选,即独立的,则每个用户有自己的值:比如用户 #1 获取值为 1,用户 #2 获取值为 2。
每次迭代复原计数器(Reset counter on each Thread Group Iteration):可选,仅勾选与每用户独立的跟踪计数器时可用;如果勾选,则每次线程组迭代,都会重置计数器的值,当线程组是在一个循环控制器内时比较有用。
CSV 数据文件配置
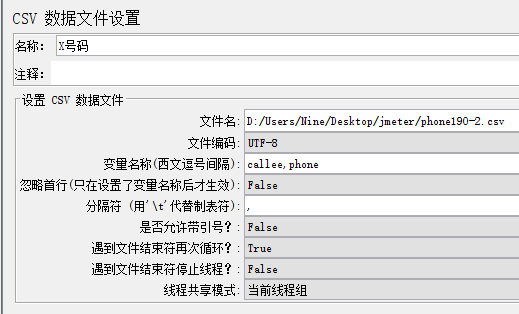
文件名:导入你的数据文件绝对路径
文件编码:一般选UTF-8
变量名:多个变量中间用英文的逗号隔开
忽略首行:同Excel,首行为标题栏选 True
分隔符:数据文件里面分割参数的符合,一般用英文逗号
是否运行带引号:一般不用改,默认Fasle
遇到文件结束符时循环:是否重复使用数据文件
遇到文件结束符时停止线程:相当于读取文件内所有行后停止,如注册
线程共享模式:默认所有的线程就行
JDBC 请求
https://www.cnblogs.com/Sweettesting/p/13787286.html
- 本文作者:Nine
- 本文链接:https://blog.nine.gt.tc/2020/10/23/jmeter-skill/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)